
What We Delivered for Our Serverless Data Stack
Re-Cap
(This is the fourth article in our series, "Behind the Build." Check out the first, second, and third articles in the series if you haven't already!)
Let’s recap a bit about what we covered so far.
The project required building an open-source data lakehouse for a global humanitarian organization under strict constraints, no vendor-locked software beyond AWS and GitHub, minimal costs, and a preference for open-source tools. We chose DuckDB for querying, SQLMesh for transformations, and S3 for storage.
Key challenges emerged around versioning and environment management. Iceberg was considered but dropped due to DuckDB’s lack of write support and the need for a metadata catalog. Instead, we relied on S3’s native versioning. SQLMesh’s virtual environments required persistent metadata storage, but without a centralized warehouse, we stored entire DuckDB files in S3 as a workaround.
This experience highlighted the trade-offs between cutting-edge open-source tools and practical implementation constraints, shaping a scalable, cost-effective architecture.
Solution Highlights
Let’s take a look at what we delivered for the client in terms of its architecture and the development workflow. Our solution included, but was not limited to the following components that enabled our client’s developers to effectively work in isolation while ensuring collaboration and reproducibility:
ELT with a combination of custom Python scripts and SQLMesh → Allowed flexible transformations while ensuring version control and consistency across environments.
A centralized data lake on S3 → Provided a single source of truth, with structured zones (dev, qa, and production) to manage data lifecycles efficiently.
CI/CD and cron jobs with GitHub Actions → Automated deployments, enforced code quality, and minimized manual intervention.
Here’s an example development workflow:
A developer uploads source files to the data folder. The developer runs the Python script to upload the source files from the data folder into the dev landing zone in S3.
The developer builds and executes models in SQLMesh, which uploads specified models into the dev staging zone in S3 (via SQLMesh’s post-statements written in Python macros).
The developer pushes the changes to the GitHub repo, creates a PR, gets it reviewed, and merged. Changes to the code are deployed to production once the PR is merged. GitHub Actions CI/CD pipelines are executed during this process.
A daily cron job in GitHub Actions picks up the updated code and runs the pipeline. This is when the new data reflecting the production code will be pushed to production, outputting files into the prod zone in S3.

To enhance usability and ensure a consistent development experience across all developers, our solution is designed to work within a containerized environment. This guarantees a uniform setup and minimizes dependency issues. At the same time, developers can leverage the SQLMesh UI instead of running Docker commands in the terminal, making it easier to:
Inspect schema changes before applying them.
Visualize column-level lineage to understand dependencies.
Execute models and debug issues with a user-friendly graphical interface.
The workflow is designed to support collaborative model development, allowing multiple developers to contribute without interfering with each other’s work. This is achieved by separating staging and downstream models for each developer while maintaining shared raw files in the dev landing zone.
Technical Approach
Data Ingestion
It was an easy decision for us to go with Python scripts for data ingestion. The process only involves a simple file upload from a local filesystem to S3. We didn’t need any fancy SaaS tool for this. As simple as it can be, we set up a CLI command to allow the user to upload their files to S3 with ease.
Data Transformation
We chose SQLMesh as our data transformation framework. You can refer to our previous article, where we discussed some of the key reasons behind this decision. In short, we found its native support for Python particularly promising.
SQLMesh played a crucial role in meeting our client’s requirements. While it is relatively new if you compare it with tools like dbt, however, it’s miles ahead in its flexibility and a refined developer experience. This essentially made it possible for us to build models in Python using Ibis. Ibis is particularly useful in writing backend-agnostic code, based on another library called SQLGlot, which SQLMesh also relies on.
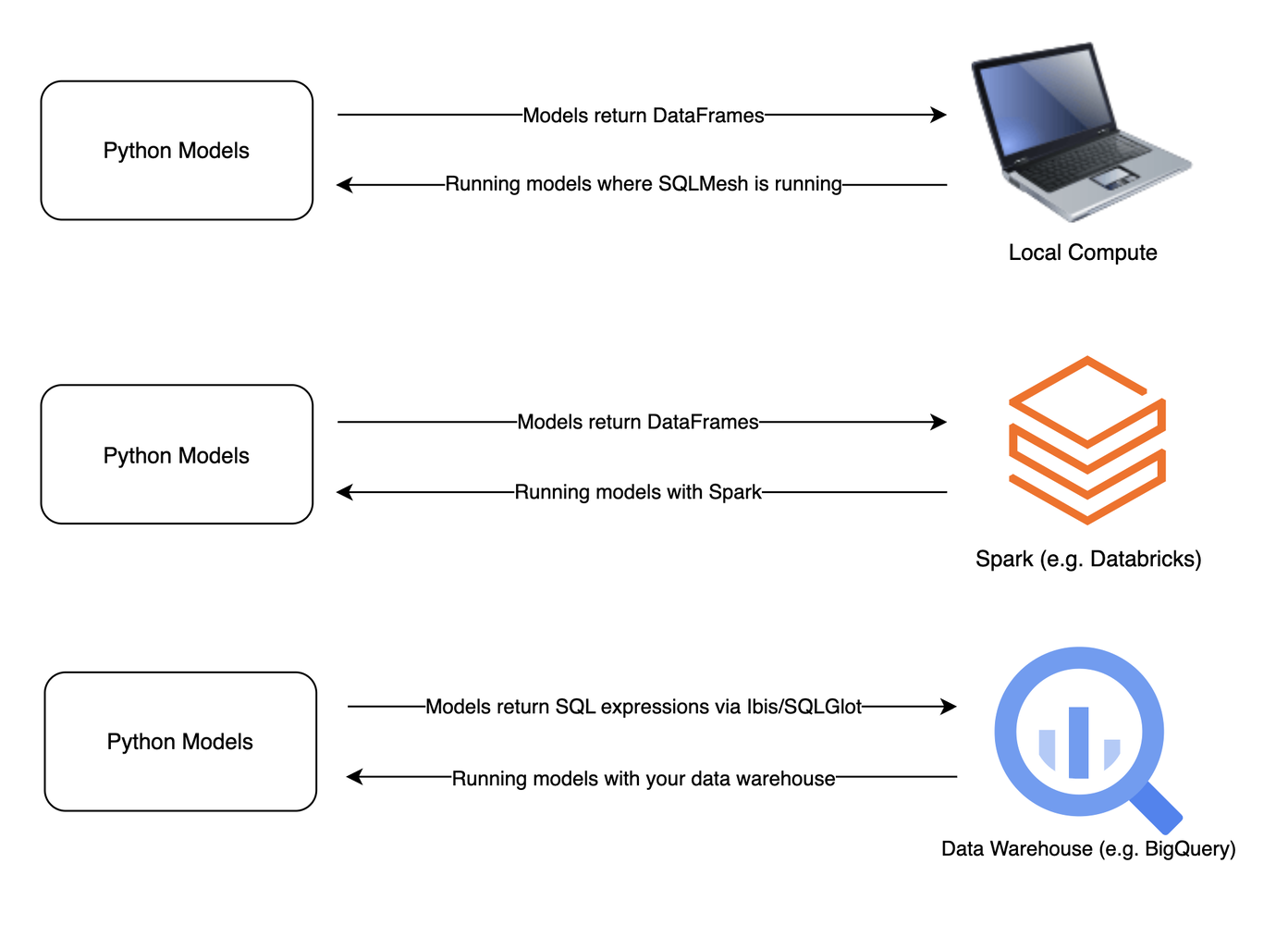
Another advantage of using Ibis in combination with SQLMesh is the fact that you can have each model return a SQL expression instead of a DataFrame. In SQLMesh, you can have your Python models return:
A DataFrame (pandas or Spark), processing data using the local compute where SQLMesh is running.
A DataFrame (pandas or Spark), processing data with the remote Spark engine (e.g., Databricks).
A SQL expression via Ibis/SQLGlot, processing data with the remote engine of your cloud data warehouse (e.g., Snowflake/BigQuery).
SQLMesh can execute Python code locally where SQLMesh is running. And the option 1 utilizes exactly that (unless you configure to use Spark as the execution engine, which is the option 2 above). If you’re running SQLMesh on your local machine, then it’d use the Python runtime configured in your SQLMesh project on your local machine.
On the other hand, option 3 allows you to build your models in Python, but instead of returning a DataFrame, you return a SQL expression (thanks to SQLGlot). This allows you to run your Python models via your data warehouse, instead of your local Python runtime.
Do you see why this is a big deal? You get to write your models in Python instead of SQL, taking advantage of its flexibility, and run them using the powerful engine of your choice. With Ibis, you can do this seamlessly in SQLMesh.
If our project needs to scale in the future with a cloud data warehouse like Snowflake or BigQuery, no problem. Just update the configuration, and our Python models written in Ibis will run without changing a single line of code.
That said, it’s worth noting that in our current setup, having Python models return SQL expressions doesn’t give us a huge advantage, since we're running DuckDB locally. Even though the models' queries go through a data warehouse engine (in this case, local DuckDB), everything still runs on local compute.
Another thing to note is that the first-class Python support in SQLMesh also made it possible for us to build custom scripts/macros to read from and write to S3. While this could technically be done with dbt-duckdb, you’d be limited by the level of integration dbt-duckdb provides. With SQLMesh, it’s possible to use open table formats like Iceberg or Delta even without native write support in DuckDB. The reason is that you can simply write your custom script as SQLMesh Python macros using delta-rs or pyiceberg (pending how we’d manage the iceberg catalog), and attach them as post-statements to your models.
GitHub Actions for CI/CD and orchestration
We chose GitHub Actions for implementing CI/CD pipelines as well as setting up the daily cron job. Our project doesn’t build a complex DAG and run models on a cron job. Using GitHub Actions made total sense for our use case. Could we have used a fully-featured orchestration tool like Airflow, Prefect, or Dagster? Yes absolutely. But why would you complicate the data stack without a problem?
Misc: Persistent DuckDB database in S3
If you think about the developer workflow, each developer has their files that they upload to S3, build models they care about, and execute them locally. This exposes certain models in S3 for further consumption. This is all good and fine on paper, however, there is one issue. Without a shared DuckDB state, each developer and environment ends up managing their disconnected database file, leading to inconsistency and a fragmented state. Our conclusion was to give a bit more consistency in the workflow that provides each developer a reliable starting point.
So, what we decided to do is to persist the production DuckDB database on S3, and build a process that allows each developer to download the prod copy and QA/prod processes to update the production DuckDB database in S3.
This gave us a few benefits:
A consistent starting point for each developer
The use of SQLMesh’s virtual data environments
The first bullet point may be obvious, but how is this utilizing virtual data environments? Now that QA and prod processes are based on the same DuckDB instance, once you run models in QA, the prod process doesn’t need to execute the models again. It just needs to switch the pointer, which is the whole point of virtual data environments. Also, since you have everything in QA/prod environments, when the developer copies down the production DuckDB file to start working locally, the creation of a dev environment in SQLMesh is essentially free (no need to execute models locally).
We know we’re not using virtual data environments to their full extent, but we’re happy that we were able to find a way to still utilize them in our solution!
It’s worth noting that persisting the DuckDB file was possible given the scope and data size for the project.
Outcomes & Impact
Immediate Benefits for the Organization
This setup immediately boosted efficiency by automating transformations and deployments, freeing developers from repetitive tasks so they can focus on modelling and analysis. Isolated staging zones improved collaboration by allowing independent work without conflicts, while SQLMesh ensured consistent, high-quality data across environments.
This isn’t just a one-off solution—it’s a scalable, cost-effective model that other organisations, especially those with tight budgets and a preference for open-source tools, can adopt. It avoids costly SaaS platforms, supports smooth transitions to cloud warehouses like Snowflake, and ensures security and compliance through S3 versioning and private containers for controlled access and change tracking.
Schema Changes & Lineage
A major advantage of this setup is the ease of tracking changes and dependencies. Developers can preview and validate schema changes before deployment, minimizing errors. SQLMesh also offers column-level lineage, giving clear visibility into data flow across models, which simplifies debugging and optimization.
Developer-Friendly UI
Instead of relying on terminal commands, developers can use SQLMesh’s intuitive UI to run models and inspect outputs, streamlining execution without complex CLI workflows. The UI also speeds up debugging by highlighting issues clearly, and version control enhances collaboration by showing exactly who changed what and when.
Collaborative Model Development
The setup supports seamless collaboration by giving each developer an isolated workspace, preventing accidental disruptions to others’ work. Raw data lives in a shared dev landing zone, while structured data flows through staged and production environments, ensuring consistency and a clear path from development to deployment.
What We Learned
Simple beats fancy: Python scripts for ingestion got the job done without the overhead of a SaaS tool.
Compatibility is key: SQLMesh and S3 played well together, but managing metadata took extra planning.
Think ahead: The modular approach ensures that the foundation is already in place if more storage or compute power is needed.
What's Next?
So, what’s next? We plan to keep developing this solution as an open-source project. Our current solution is nowhere near perfect. We’ll keep improving and iterating on the solution as we get more feedback from the client and other potential users in the wild. We also plan on inviting external contributions to the repo in the future. If you’re interested, please reach out to us!